
During the LLM hype, you can find a lot of articles like “Fine-tune your Private LLaMA/Falcon/Another Popular LLM”, “Train Your Own Private ChatGPT”, “How to Create a Local LLM” and others.
At the same time, only few people tell why you need it. I mean, are you really sure you need your own self-hosted LLM? Maybe the OpenAI API could be the best choice for you.
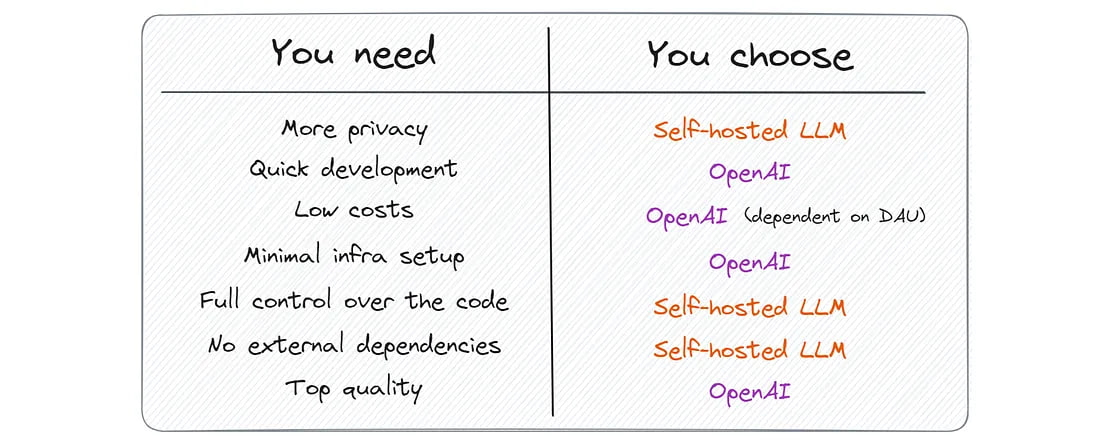
In this article, I will compare two approaches to using LLMs: making API calls to OpenAI versus deploying your own model. We will discuss aspects such as cost, text generation quality, development speed, and privacy.
Disclaimer: The information in the article is current as of August 2023, but please be aware that changes may occur thereafter.
Economics
Self-hosted
As an illustration, let’s consider LLaMA-2–70B. It’s worth noting that most companies employ smaller model versions and fine-tune them according to their tasks. However, I intentionally choose the largest version because it’s the only model that can match the quality of GPT-3.5.
For its deployment it is better to use 8x Nvidia A100, so we will need either g5.48xlarge on AWS or a2-megagpu-16g on GCP. The prices are listed below:

It’s important to consider that these aren’t the only providers; you can also explore alternative options using [this service](https://cloud-gpus.com/). However, they are among the most commonly used in the industry.
Additionally, let’s include the following extra expenses to the server cost:
• Payment for DevOps specialists who will handle server setup, load balancing, and monitoring.
• Payment for ML engineers responsible for model preparation, maintenance, and fine-tuning.
• Optionally, one-time payment for dataset collection and annotation for fine-tuning.
We can estimate this to be approximately $40k — $60k per month on GCP for inference LLaMA-2–70B.
OpenAI API
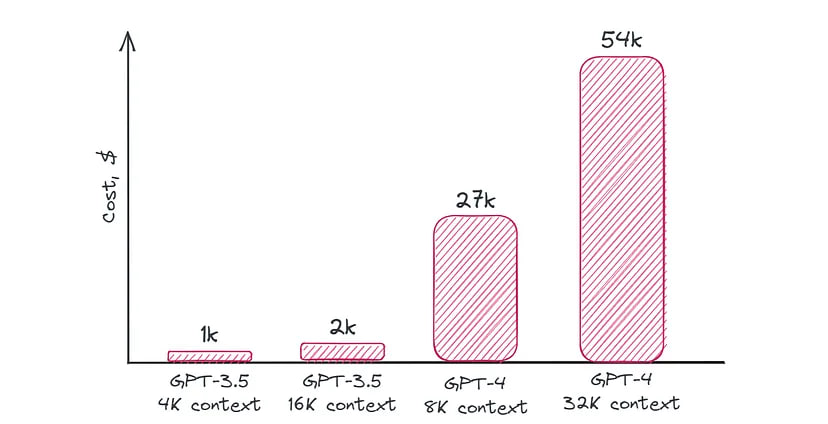
Now let’s calculate the cost of generating text using the OpenAI API:

For a better understanding of the price: 10,000 customer queries per day then costs ($0.0015 + $0.002) * 10,000 * 30 =~ $35 a day, or $1000 a month.
For lower usage in the 10,000’s requests per day range, OpenAI API works out cheaper than using self-hosted LLMs.
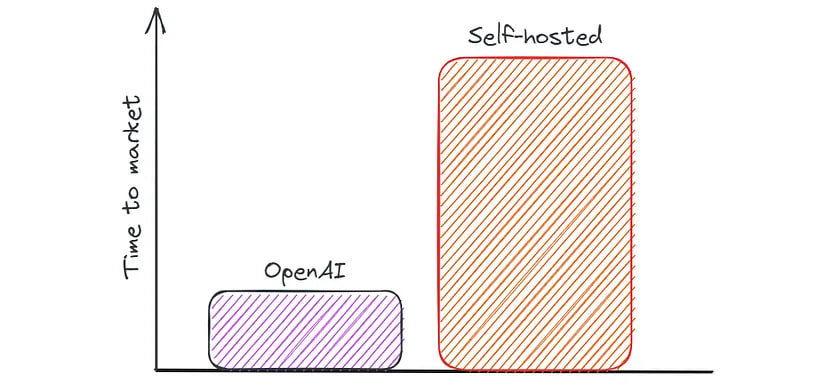
This can be shown schematically in the following picture:
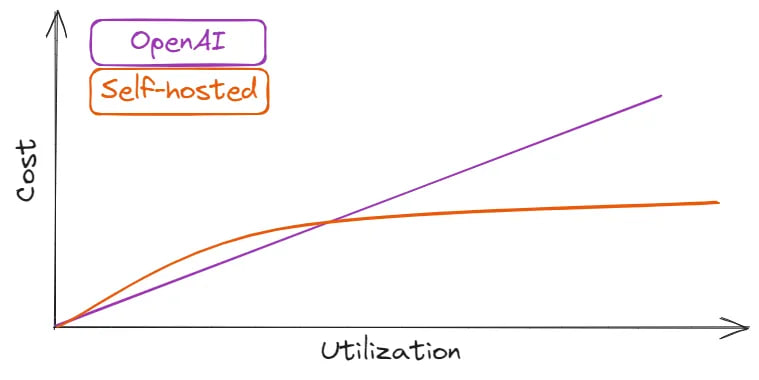
Of course, it is possible to use various techniques to reduce the model size: quantization, pruning, mix-precision, etc. However, such methods are lossy, meaning some performance degradation.
In conclusion, if you have a small amount of daily active users (<10,000), using the OpenAI API would be the optimal choice.
Quality
Even though open-source models are being actively developed, they are still worse in quality than GPT-3.5 and GPT-4. Both on standard benchmarks:
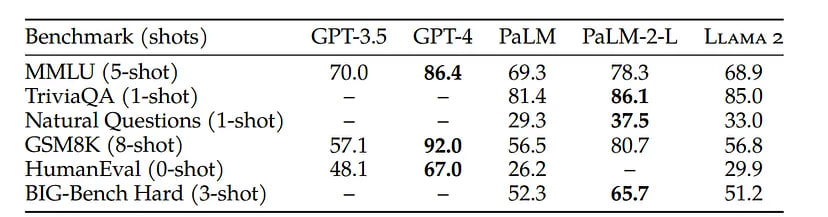
And on different domain tasks:
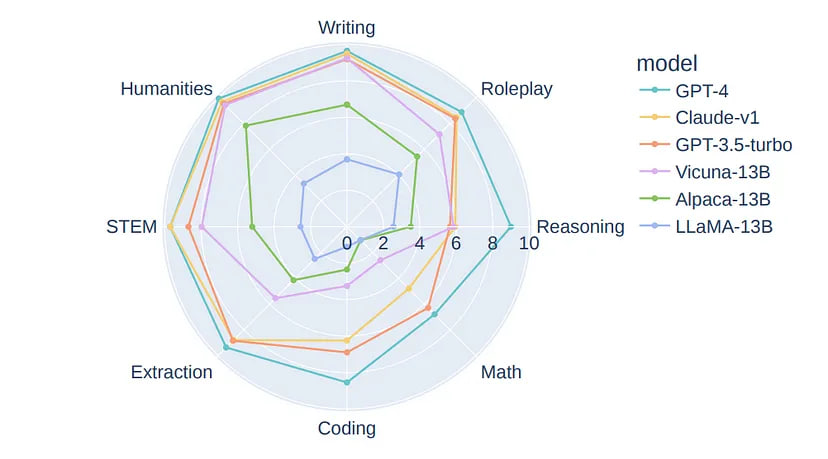
I believe that in the near future, we will witness a significant increase in the accuracy of new models, thanks to the active involvement and support of the community.
However, at this moment, if you want to unlock the full potential of LLMs, it’s advisable to use the OpenAI API.
Time to market
Everyone who has been involved in app development knows how much time it can take to write high-quality code that can reliably perform under heavy loads. The cost and complexity of deploying open-source LLMs into production are considerably higher compared to using a ready-made API. You don’t need to worry about load balancing, resource monitoring, horizontal scaling, and much more.
So if you want to build a quick prototype and test a hypothesis, the best solution is to use the OpenAI API.
Privacy
This is probably one of the key factors why most companies choose to use self-hosted LLMs. OpenAI’s Terms of Use mentions that they “may use Content from Services other than our API … to help develop and improve our Services”:

This means that anything you send to ChatGPT, will be included in their training data. Despite efforts to anonymize the data, it still contributes to the knowledge of the model.
For example, Avast published an article emphasizing the fact that once a model uses a user’s data to learn from it, it was very hard (even impossible for now) to delete it. Many companies have already prohibited their employees from using ChatGPT, including notable names like Samsung, Apple, JPMorgan, and others.
If you do not want your Content used to improve Services, you can opt-out by filling out this form Or you can use the Azure OpenAI Service. This is the exact same service as ChatGPT, but offered as open source with private Azure hosting, so you’re not sharing data with OpenAI. If your company is already on Azure, this is a no-brainer for LLM chatbot adoption.
On the other hand, OpenAI claims that they do not use data sent through the API to train the model or improve services. However, one cannot be sure that they will not change this position in the future.
In conclusion, if you deal with sensitive data, you should definitely use self-hosted LLMs or use Azure OpenAI Service.
Control
With a self-hosted solution, you are in complete control of your application. Only your team is responsible for system uptime. By using an external API, you add a new dependency that is harder to control:
• Response times can vary based on load.
• A failure in an external service can affect your application.
• API quota limits could be raised unexpectedly, as illustrated by a developer’s experience.
Below is the uptime record for the OpenAI API over the past 90 days. On days marked with a color other than green, your application would have been unavailable for periods ranging from 10 minutes to several hours.

Using open-source models provides more control and transparency as organizations have access to the underlying code and can modify it as needed. This level of customization can be valuable for companies with specific privacy, security, or compliance requirements.
Closing thoughts
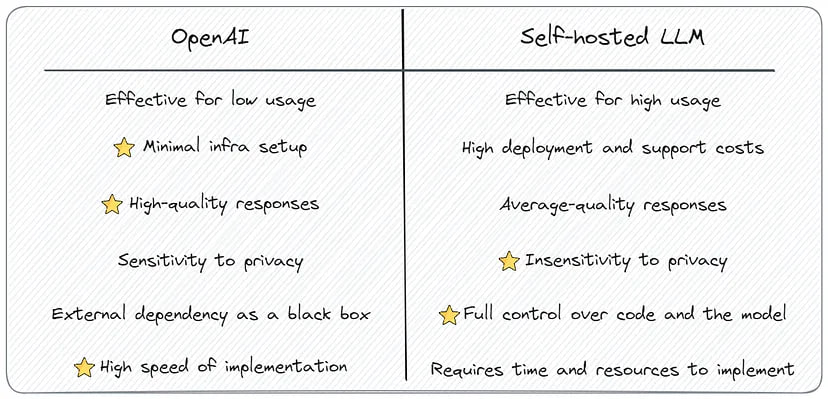
In this matter, there is no clear-cut answer about what is better: OpenAI or self-hosted LLM. It depends on the specific needs, resources, and priorities. Evaluating factors such as performance, customization, data privacy, and compliance dictates the right approach for utilizing LLMs. Hosted models are necessary for privacy, reliability, or compliance, while OpenAI proves advantageous for rapid prototyping and hypothesis testing, especially if extensive requirements and high workloads are not expected.
My recommendation is to start by creating a prototype using OpenAI’s API and then gradually replace some functionalities with self-hosted models.
Furthermore, you can even use a combination of these approaches by setting up a chain of model calls. The subject of combining and creating chains is quite complex and necessitates a dedicated article to fully address.