
Generative Large Language Models (LLMs) can generate highly fluent responses to various user prompts. However, their tendency to hallucinate or make non-factual statements can compromise trust.
I think we will get the hallucination problem to a much, much better place… it will take us a year and a half, two years — OpenAI CEO Sam Altman
As developers look to build systems with models, these limitations present a real challenge as the overall system must meet quality, safety, and groundedness requirements. For example, can we trust that an automatic code review provided by an LLM is correct? Or the returned answer to questions on how to handle insurance-related tasks is reliable?
This article begins with an overview of how hallucination remains a persistent challenge with LLMs, followed by steps (and associated research papers) that address hallucination and reliability concerns.
Disclaimer: The information in the article is current as of August 2023, but please be aware that changes may occur thereafter.
“Short” Summary
Hallucinations in Large Language Models stem from data compression and inconsistency. Quality assurance is challenging as many datasets might be outdated or unreliable. To mitigate hallucinations:
- Adjust the temperature parameter to limit model creativity.
- Pay attention to prompt engineering. Ask the model to think step-by-step and provide facts and references to sources in the response.
- Incorporate external knowledge sources for improved answer verification.
A combination of these approaches can achieve the best results.
What Is an LLM Hallucination?
A research paper from the Center for Artificial Intelligence Research defines a hallucination from an LLM as “when the generated content is nonsensical or unfaithful to the provided source content.”
Hallucinations can be categorized into several types:
- Logical Fallacies: The model errs in its reasoning, providing wrong answers.
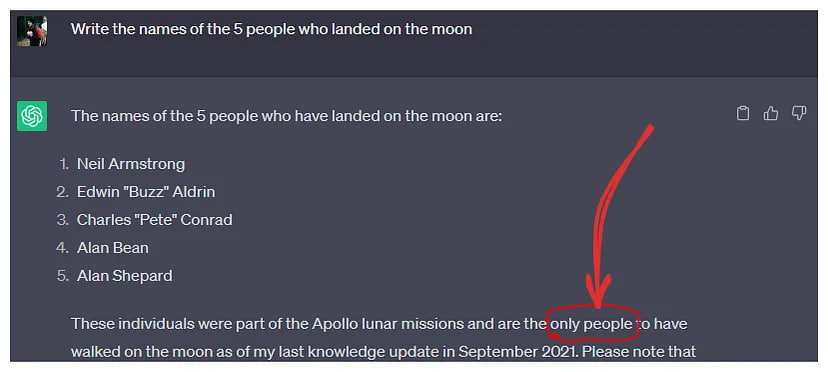
- Fabrication of Facts: Instead of responding with “I don’t know,” the model confidently asserts non-existent facts. Example: Google’s AI chatbot Bard makes a factual error in the first demo.
- Data-driven Bias: The model’s output may skew due to the prevalence of certain data, leading to incorrect results. Example: Political Biases Found in NLP Models.
Why LLMs Hallucinate
I liked the concept in this article: as we compress training data, models will inevitably hallucinate. Consider the compression ratios for some popular models:

Of course, the key to this compression is that a generative model stores a mathematical representation of the relationship (probabilities) between input (text or pixels) instead of the input itself. More importantly, this representation lets us extract knowledge (by sampling or running queries/prompts).
Such compression reduces fidelity, similar to JPEG compression, as discussed in the New Yorker article. In essence, full recovery of the original knowledge becomes a difficult, if not impossible, task. Models’ tendency to imperfectly ‘fill in the blanks’ or hallucinate is the trade-off for such a compressed but helpful representation of knowledge.
LLMs also hallucinate when their training dataset contains limited, outdated, or contradictory information about the question posed to them.
Preparing for the Experiment
This article aims to create and test practical steps to reduce hallucination and improve the performance of systems. For this purpose, after reviewing various datasets, I settled on the TruthfulQA Benchmark.

While the dataset has issues, such as discrepancies between correct answers and their sources, it remains the most suitable option due to its variety of topics and comprehensive coverage. I also appreciate that answers come in a quiz format, facilitating model testing. One can easily request the answer in JSON format:
… Return response in JSON format, for example: [{“class”: “A”}]
I used a dataset with 800 rows, using GPT-3.5 turbo for its cost-effectiveness.
Other benchmarks for evaluating hallucination
• Knowledge-oriented LLM Assessment benchmark (KoLA)
• TruthfulQA: Measuring How Models Mimic Human Falsehoods
• Medical Domain Hallucination Test for Large Language Models
• HaluEval: A Hallucination Evaluation Benchmark for LLMs
Temperature Reduction
A model’s temperature refers to a scalar value used to adjust the probability distribution predicted by the model. In the case of LLMs, it balances between sticking to what the model has learned from the training data and generating more diverse or creative responses. Generally, these creative answers are more prone to hallucinations.
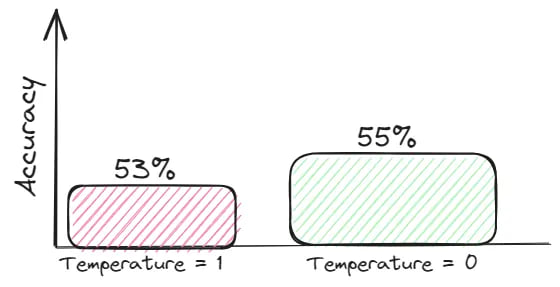
For tasks that require veracity, strive towards an information-dense context and set temperature=0 to get answers grounded in context.
Chain of Thought Prompting and Self-Consistency
Benchmark errors can often be fixed by improving your prompt design. That’s why I paid more attention to this topic.
LLMs often falter on multi-step reasoning tasks, like arithmetic or logic. Recent works indicate that providing examples of breaking the task into steps boosts performance. Remarkably, just prompting with “Let’s think step by step” without specific examples yields similar improvements.
Many articles delve into thought-chaining techniques. Essentially, they aim to make the model think step by step and self-verify. Below are some standout approaches:
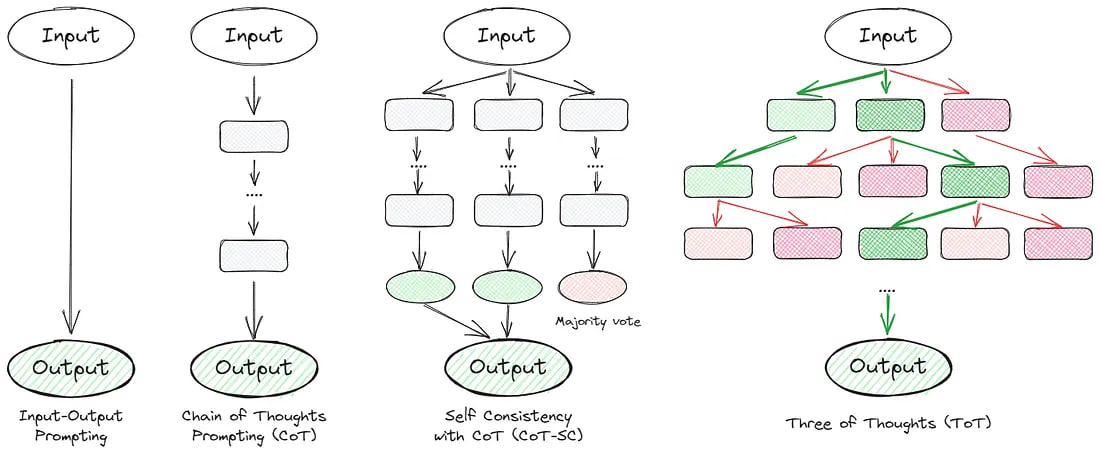
Now, let’s delve into each method and evaluate their quality on the dataset.
1. Chain of Thoughts (CoT)
The main idea of the article is to add “Think step by step” to the prompt:
Think step by step before answering and return response in JSON format, for example: [{“class”: “A”}]”
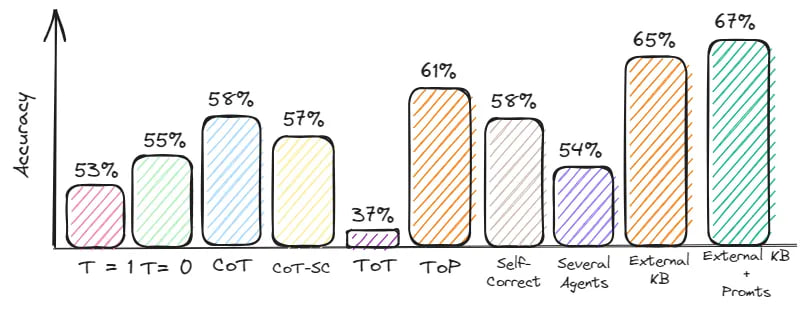
Evaluation: Accuracy = 58%
2. Self Consistency with CoT (CoT-SC)
The approach is an improved version of the previous idea. We ask the model to give several answers and then choose the best one by voting:
Think step by step before answering and give three answers: if a domain expert were to answer, if a supervisor were to answer, and your answer. Here’s the response in JSON format:
Evaluation: Accuracy = 57%
3. Tree of Thoughts (ToT)
It is a framework that generalizes over chain-of-thought prompting and encourages the exploration of thoughts that serve as intermediate steps for general problem solving with language models. This approach enables an LM to self-evaluate the progress intermediate thoughts make toward solving a problem through a deliberate reasoning process. A sample ToT prompt is:
Imagine three different experts are answering this question. All experts will write down 1 step of their thinking, then share it with the group. Then all experts will go on to the next step, etc. If any expert realises they’re wrong at any point then they leave. Here’s the response in JSON format:
Evaluation: Accuracy = 37%
4. Tagged Context Prompts
The method includes generating question sets, creating context prompts through summaries, and verifying context prompts and questions.
Given the complexity of additional dataset generation, I adjusted my approach to request the source link and facts:
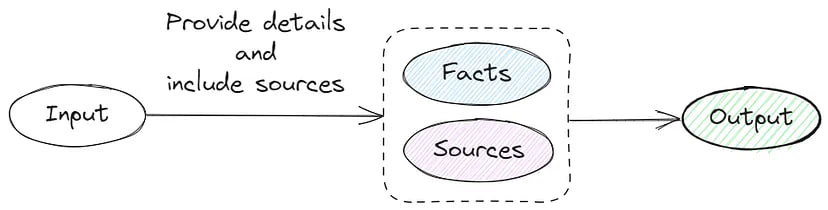
Provide details and include sources in the answer. Return response in JSON format, for example:
[{“class”: “A”, “details”: “Human blood in veins is not actually blue. Blood is red due to the presence of hemoglobin”, “source”: “https://example.com"}]
Evaluation: Accuracy = 61%
5. Self-Correct
It may be one of the more advanced techniques for prompt engineering. The idea is to get the model to double-check and criticise its results, which you can see below:
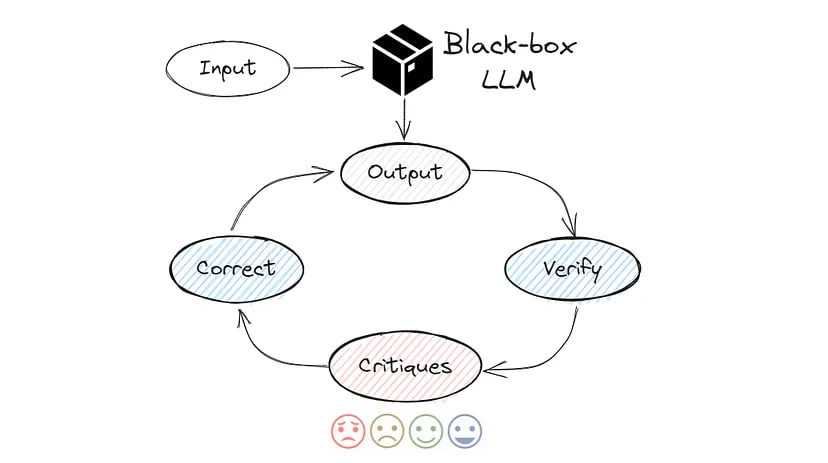
Choose the most likely answer from the list [“A”, “B”, “C”, “D”, “E”]. Then carefully double-check your answer. Think about whether this is the right answer, would others agree with it? Improve your answer as needed.
Return response in JSON format, for example: [{“first_answer”:”A”, “final_answer”:”B”}]
Evaluation: Accuracy = 58%
6. Several Agents
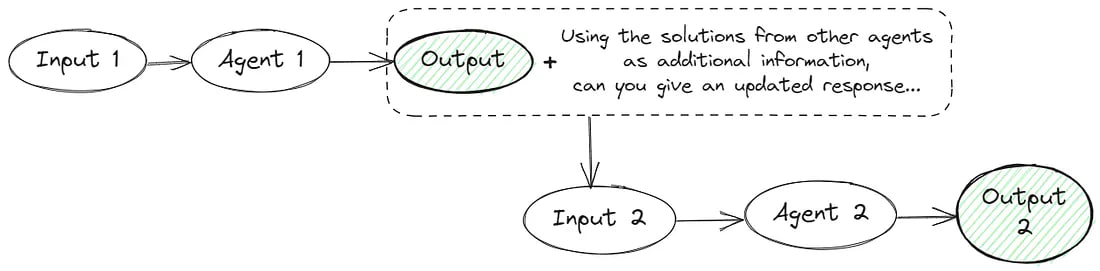
Multiple language model instances propose and debate their individual responses and reasoning processes over multiple rounds to arrive at a common final answer. This approach includes several prompts:
Prompt 1
Give the facts and your thoughts step by step to find the right answer to this question: {QUESTION}
Prompt 2
Using the solutions from other agents as additional information, choose the correct answer choice: {QUESTION} {ANSWERS}. Return response in JSON format…
Evaluation: Accuracy = 54%
I would not recommend using this approach in real applications because you need to make two or more requests. This not only increases API costs but also slows down the application. In my case, it took more than two hours to generate responses to 800 questions.
Use An External Knowledge Base
As mentioned, hallucination in LLMs stems from attempting to reconstruct compression information. By feeding relevant data from a knowledge base during prediction, we can convert the pure generation problem to a simpler search or summarization problem grounded in the provided data.
Since, in practice, retrieving relevant data from a knowledge base is non-trivial, I focused on a small sample (~300 rows) from the dataset I had collected.
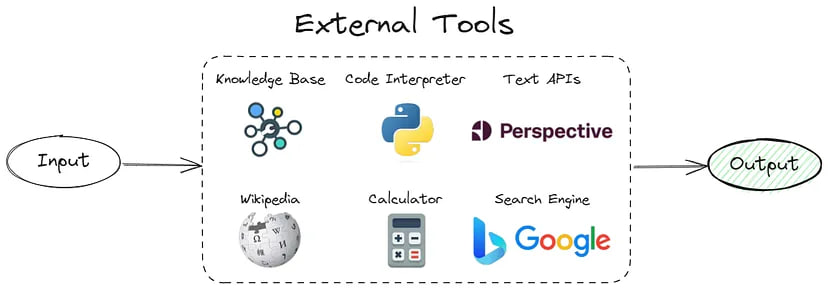
In the end, my prompt looked like this:
Using this information {INFORMATION} choose the correct answer {QUESTION} and return response in JSON format…
Evaluation: Accuracy = 65%
More work is still needed to filter/rank retrieved passages and decide how much of the LLM context budget is used in this exercise. Also, retrieval and ranking can introduce delays crucial for real-time interactions.
Another interesting approach is Retrieval-Augmented Generation (RAG), which merges the capabilities of retrieval and text generation in Large Language Models. This approach pairs a retriever system for fetching relevant document snippets from a vast corpus with an LLM that generates answers based on the retrieved information.
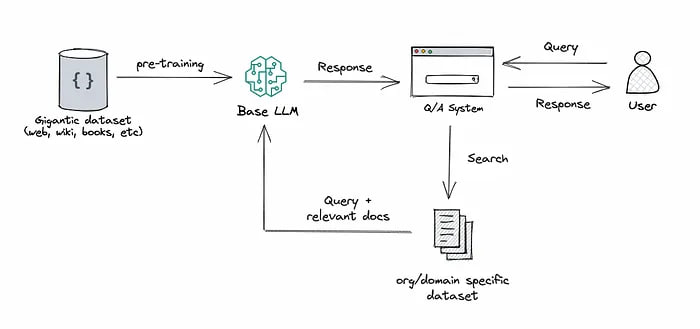
Some related articles
• Hypothetical Document Embedding (HYDE) — Paper proposes using the initial answer from an LLM as a soft query in retrieving relevant passages
• Mitigating Language Model Hallucination with Interactive Question-Knowledge Alignment
• RAG vs Finetuning — Which Is the Best Tool to Boost Your LLM Application?
Prompt Engineering and External Knowledge Base
This approach combines the previous points. Different techniques of prompt engineering and external knowledge base are used. I implemented logic from the CRITIC framework:
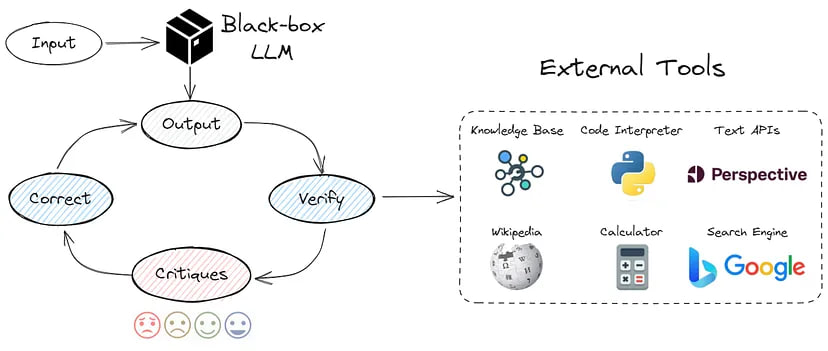
Using this information {INFORMATION} choose the correct answer {QUESTION} Then carefully double-check your answer. Think about whether this is the right answer, would others agree with it? Improve your answer as needed.
Return response in JSON format, for example: [{“first_answer”:”A”, “final_answer”:”B”}]
Evaluation: Accuracy = 67%
Although the quality has not improved that much, this is due to the problems in the dataset I used. Some “correct” answers don’t match the information from the sources.
Takeaways
At first glance, reducing hallucinations in LLMs is not rocket science: adjust the temperature, play with prompts, and link external data sources. However, as with many things, nuances abound. Each method has its strengths and drawbacks.
My key recommendation? Prioritize prompt design — it’s the most cost-effective and efficient way to fix hallucinations.
References
- Practical Steps to Reduce Hallucination and Improve Performance of Systems Built with Large Language Models — One of the best articles I’ve found.
- [Reading list of hallucinations in LLMs] — A useful GitHub repository with various links about hallucinations in LLMs.