
It’s almost impossible to distinguish between human-written text and large language model (LLM) generated text. Given the potential chaos that can result from the spread of misinformation, fake news, phishing, and social engineering, finding ways to identify LLM-generated text and verify its content is crucial.
This article aims to provide an overview of existing methods for detecting generated text, highlight their limits, and conduct benchmarks of existing services.
Disclaimer: The information in the article is current as of September 2023, but please be aware that changes may occur thereafter.
“Short” Summary
- As of now, there is no 100% reliable method for effectively detecting AI-generated text.
- Many detectors perform poorly when the text is paraphrased , the language is changed, or some words are replaced.
- The issue is increasingly relevant because future LLMs will require more text in their training data. If the models are trained on their own generated data, the results could be problematic.
- Always make an effort to independently verify facts and source citations, check dates, and evaluate the believability of the content.
- This paragraph was generated by ChatGPT, but you’ll never know because I asked it to paraphrase the message.

Why it’s important to detect AI-generated content
While preparing this article, I came across numerous opinions emphasizing the importance of detecting AI-generated content, mainly because students could use it to generate homework and even theses. Real-world examples exist: a professor accused his class of using ChatGPT, putting diplomas in jeopardy and a Russian Student Allowed to Keep Diploma for ChatGPT-Written Thesis. On the flip side, we have all been students at some point and many have found alternative ways to bypass academic requirements.
I would highlight other issues:
- The tendency of LLMs to hallucinate can lead to misleading information. These could be particularly dangerous if the articles are related to medicine or science.
- Generating a large volume of content using various LLMs could introduce bias into the training data of next GPT-X generations.
- I don’t like receiving AI-generated emails (which, incidentally, was the catalyst for writing this article). Feels like you’re talking to a support bot.
I hope I was able to convince you that this is important. Now let’s see how we can detect generated text.
Methods for detecting LLM-generated text
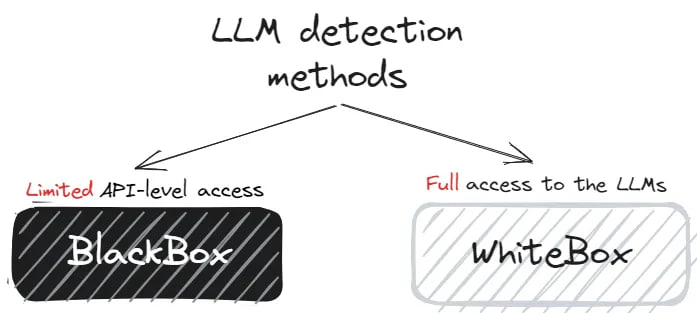
Detection methods for LLM-generated content can be grouped into two categories: black-box detection and white-box detection:
• Black-box detection — Limited API-level access to LLMs. It is necessary to collect text samples from human and machine sources to train a classifier.
• White-box detection — The detector has full access to the LLMs and can control the model’s generation behavior for traceability purposes.
Each method has its own approaches and modifications. While the problem of white-box detection has been largely solved, black-box detection remains a complex challenge. Various strategies are being used to tackle it: changing the type of classifier, generating additional features, and even compressing the data. We will discuss these approaches in more detail below.
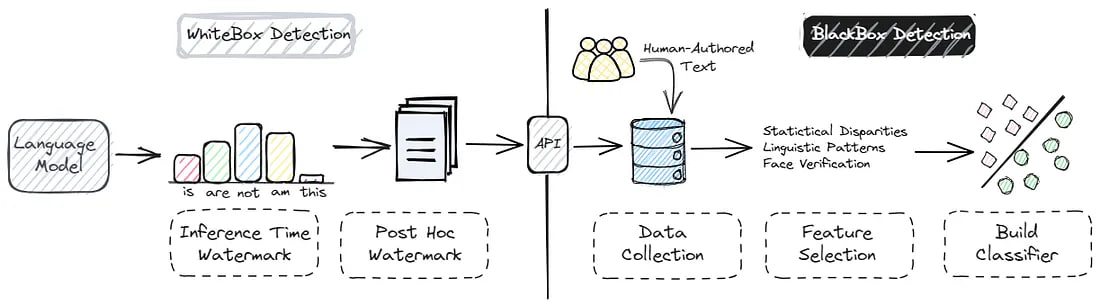
White-box detection
Watermarking
The proposed watermarking strategy reduces the likelihood of specific words appearing in LLM outputs by reducing their probabilities, essentially creating an “avoid list”. If a text features these lower-probability words, it’s probably human-generated, as LLMs are programmed to sidestep these terms.

Post-hoc Watermarking
Post-hoc watermarks insert a hidden message into LLM-generated text for later verification. To check for the watermark, one can extract this hidden message from the text in question. These watermarking methods primarily fall into two categories: rule-based and neural-based.
Inference Time Watermark
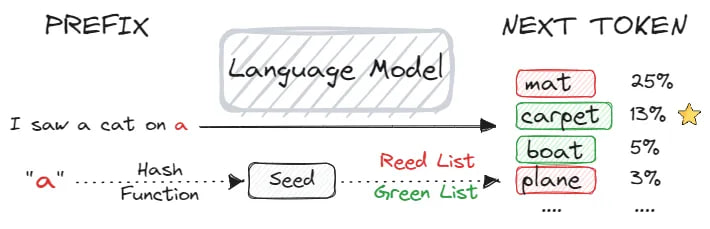
This method alters the word selection during a decoding phase. The model creates a probability distribution for the next word, and embeds a watermark by tweaking this selection process. Specifically, a hash code generated from a previous token categorizes vocabulary into “green list” and “red list” words, with the next token chosen from the green list.
In the illustration bellow, a random seed is generated by hashing the previously predicted token “a”, splitting the whole vocabulary into “green list” and “red list”. The next token “carpet” is chosen from the green list.
Limitations
Implementing this approach assumes users are working with a modified model, which is unlikely. Furthermore, if the avoid list is public, one could manually add these words to AI-generated text to evade detection.
You can try generating text with watermarks by using the Hugging Space Gradio Demo or you can check out the GitHub repository for running the Python scripts on personal machine.
Sources:
• On the Reliability of Watermarks for Large Language Models
• The Science of Detecting LLM-Generated Texts
• A Watermark for Large Language Models
Black-box detection
The core of this approach involves creating a binary classifier.The task is similar to traditional machine learning, where the model’s accuracy depends on the variety of the data and the quality of the feature set.
I’ll delve into several interesting implementations.
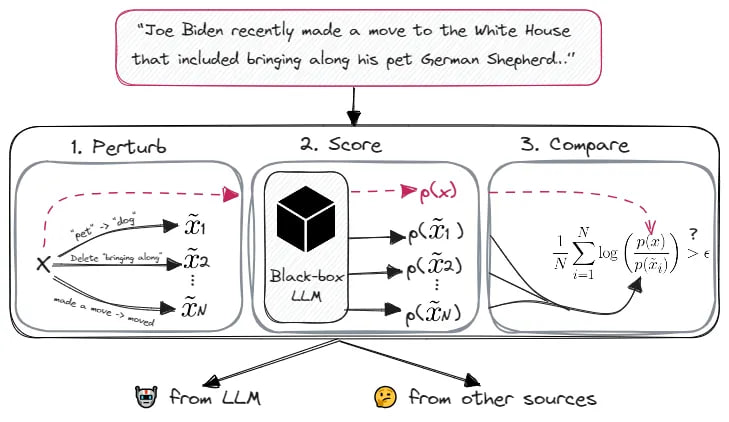
1. DetectGPT
DetectGPT calculates the log-probabilities of a text’s tokens, considering the probabilities conditional on preceding tokens. By multiplying these conditional probabilities, it obtains the joint probability of the text.
The method then alters the text and compares probabilities. If the new text’s probability is significantly lower than the original’s, the original text is likely AI-generated. If the probabilities are similar, the text is likely human-generated.
Paper & Demo (for GPT-2) & GitHub
2. GPTZero

GPTZero is a linear regression model designed to estimate text perplexity. Perplexity is tied to the text’s log-probability, much like in DetectGPT. It’s calculated as the exponent of the text’s negative log-probability. Lower perplexity indicates less random text. LLMs aim to reduce perplexity by maximizing text probability.
Unlike previous methods, GPTZero doesn’t label text as AI-generated or not. It provides a perplexity score for comparative analysis.
Blog & Demo GPTZero & Open Source version
3. ZipPy
ZipPy uses Lempel–Ziv–Markov (LZMA) compression ratios to measure the novelty/perplexity of input samples against a small (< 100KiB) corpus of AI-generated text.
In the past, compression has been used as a simple anomaly detection system. By running network event logs through a compression algorithm and gauging the resulting compression ratio, one could assess the novelty or anomaly level of the input. A significant change in the input will lead to a lower compression ratio, serving as an alert for anomalies. Conversely, recurring background event traffic, already accounted for in the dictionary, will yield a higher compression ratio.
4. OpenAI (no longer available)
On 31 January, OpenAI launches new tool to detect AI-generated text. According to website description, the model is a fine-tuned GPT variant that uses binary classification. The training dataset comprises both human-written and AI-written text passages.
However, the service is no longer available at this time:
What happened: OpenAI updated their original blog post, stating that they are suspending the classifier due to the low accuracy of its predictions:
As of July 20, 2023, the AI classifier is no longer available due to its low rate of accuracy.
Limitations
The main limitation of black-box methods is their rapid degradation. There’s a constant need to improve the algorithm to meet new quality standards. This issue is especially noticeable in light of OpenAI’s recent decision to shut down their detector.
Benchmarks
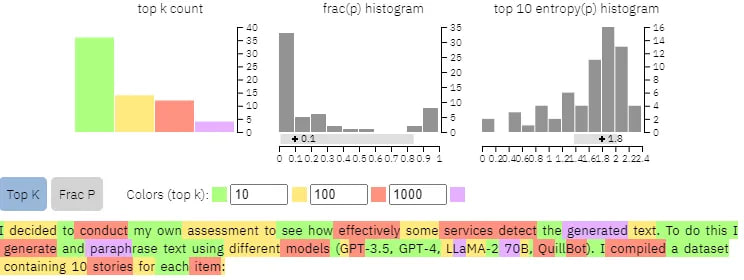
I decided to conduct my own assessment to see how effectively some services detect the generated text. To do this I generate and paraphrase text using different models (GPT-3.5, GPT-4, LLaMA-2 70B, QuillBot). I compiled a dataset containing 10 stories for each item:
• Story: “Write me a short story about …”
• Re-telling: “Rewrite and paraphrase the story …”
• Email: “Write me a short e-mail to Paul asking him …”
• Mimicry: “Explain to me like a little kid what the …”
I was astounded by the results; only a few services managed to accurately identify the generated text:

If you’re interested in exploring other research in this area, I suggest reading article “Detecting LLM-Generated Text in Computing Education”, which already provides a comprehensive comparison of these services. Here’s what the article had to say:
Our results find that CopyLeaks is the most accurate LLM-generated text detector, GPTKit is the best LLM-generated text detector to reduce false positives, and GLTR is the most resilient LLM-generated text detector… Finally, we note that all LLM-generated text detectors are less accurate with code, other languages (aside from English), and after the use of paraphrasing tools (like QuillBot).
Here’s the full list of currently available services:
• Giant Language model Test Room (GLTR)
• GPTZero
• GPTKit