
While browsing through LinkedIn, I came across a comment that made me realize the need to write a simple yet insightful article to shed light on this matter:
“Despite the hype, I couldn’t find a straightforward MLOps engineer who could explain how we can deploy these open-source models and the associated costs.” — Usman Afridi
This article aims to compare different open-source libraries for LLM inference and serving. We will explore their killer features and shortcomings with real-world deployment examples. We will look at frameworks such as vLLM, Text generation inference, OpenLLM, Ray Serve, and others.
Disclaimer: The information in this article is current as of August 2023, but please be aware that developments and changes may occur thereafter.
“Short” Summary
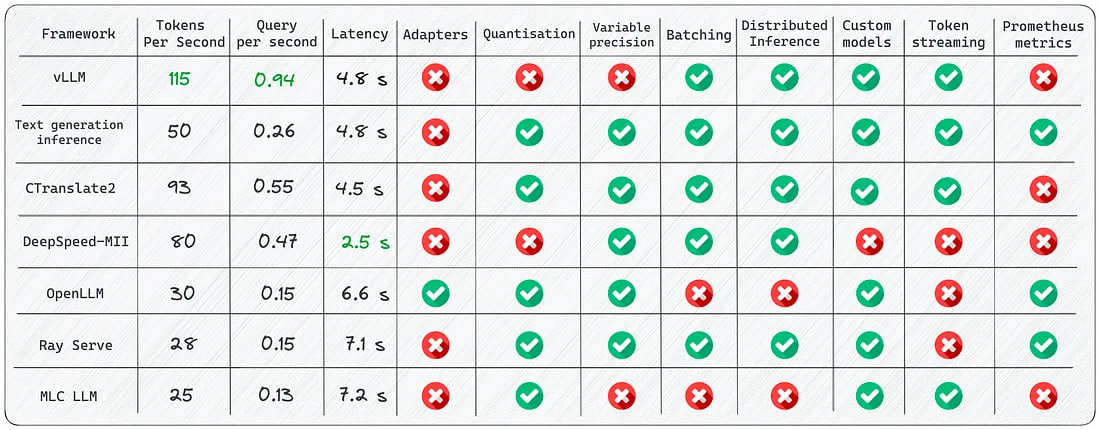
Despite the abundance of frameworks for LLMs inference, each serves its specific purpose. Here are some key points to consider:
- Use vLLM when maximum speed is required for batched prompt delivery.
- Opt for Text generation inference if you need native HuggingFace support and don’t plan to use multiple adapters for the core model.
- Consider CTranslate2 if speed is important to you and if you plan to run inference on the CPU.
- Choose OpenLLM if you want to connect adapters to the core model and utilize HuggingFace Agents, especially if you are not solely relying on PyTorch.
- Consider Ray Serve for a stable pipeline and flexible deployment. It is best suited for more mature projects.
- Utilize MLC LLM if you want to natively deploy LLMs on the client-side (edge computing), for instance, on Android or iPhone platforms.
- Use DeepSpeed-MII if you already have experience with the DeepSpeed library and wish to continue using it for deploying LLMs.
If this has caught your attention, I invite you to delve deeper and explore them in more detail.
For the hardware setup, I used a single A100 GPU with a memory capacity of 40 GB. I used LLaMA-1 13b as the model, since it is supported by all the libraries in the list.
The article will not cover traditional libraries for serving deep learning models like TorchServe, KServe, or Triton Inference Server. Although you can infer LLMs with these libraries, I have focused only on frameworks explicitly designed to work with LLMs.
1. vLLM

Fast and easy-to-use library for LLM inference and serving. It achieves 14x — 24x higher throughput than HuggingFace Transformers (HF) and 2.2x — 2.5x higher throughput than HuggingFace Text Generation Inference (TGI).
Usage
Offline Batched Inference:
# pip install vllm
from vllm import LLM, SamplingParams
prompts = [
"Funniest joke ever:",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.95, top_p=0.95, max_tokens=200)
llm = LLM(model="huggyllama/llama-13b")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
API Server:
# Start the server:
python -m vllm.entrypoints.api_server --env MODEL_NAME=huggyllama/llama-13b
# Query the model in shell:
curl http://localhost:8000/generate \
-d '{
"prompt": "Funniest joke ever:",
"n": 1,
"temperature": 0.95,
"max_tokens": 200
}'
Killer features
• Continuous batching — iteration-level scheduling, where the batch size is determined per iteration. Thanks to batching, vLLM can work well under heavy query load.
• PagedAttention — attention algorithm inspired by the classic idea of virtual memory and paging in operating systems. This is the secret sauce of model acceleration.
Advantages
• Speed of text generation — I conducted several experiments with the library and was delighted with the outcomes. As of now, inference using vLLM stands out as the fastest option available.
• High-throughput serving — various decoding algorithms, including parallel sampling, beam search, and more.
• OpenAI-compatible API server — if you used the OpenAI API, you will just need to substitute the URL of the endpoint.
Limitations
While the library offers user-friendly features and a wide range of functionalities, I have come across a few limitations:
• Adding custom models: Although it is possible to incorporate your own model, the process becomes more complex if the model does not use a similar architecture to an existing model in vLLM. For instance, I came across a pull request for adding Falcon support, which appeared to be quite challenging.
• Lack of support for adapters (LoRA, QLoRA, etc.): Open source LLMs hold significant value when fine-tuned for specific tasks. However, in the current implementation there is no option to use model and adapter weights separately, which limits the flexibility to utilize such models effectively.
• Absence of weight quantization: Occasionally, LLMs may not fit into the available GPU memory, making it crucial to reduce the memory consumption.
This is the fastest library for LLM inference. Thanks to its internal optimizations, it significantly outperforms its competitors. Nevertheless, it does have a weakness in supporting a limited range of models.
You can find vLLM Development Roadmap here.
2. Text generation inference

A Rust, Python, and gRPC server for text generation inference. Used in production at HuggingFace to power LLMs API-inference widgets.
Usage
Run web server using docker:
mkdir data
docker run --gpus all --shm-size 1g -p 8080:80 \
-v data:/data ghcr.io/huggingface/text-generation-inference:0.9 \
--model-id huggyllama/llama-13b \
--num-shard 1
Make queries:
# pip install text-generation
from text_generation import Client
client = Client("http://127.0.0.1:8080")
prompt = "Funniest joke ever:"
print(client.generate(prompt, max_new_tokens=17 temperature=0.95).generated_text)
Killer features
• Built-in Prometheus metrics — you can monitor your server load and get insights into its performance.
• Optimized transformers code for inference using flash-attention (and v2) and Paged Attention. It’s important to mention that not all models have built-in support for these optimizations. You may face challenges if you are working with a less common architecture.
Advantages
• All dependencies are installed in Docker — You immediately get a ready-made environment that will definitely work on your machine.
• Native support for models from HuggingFace — Easily run your own model or use any of the HuggingFace Model Hub.
• Control over model inference: The framework offers a wide range of options to manage model inference, including precision adjustment, quantization, tensor parallelism, repetition penalty, and more.
Limitations
• Absence of adapter support — It’s important to note that although it is possible to deploy LLMs with an adapter (I suggest referring to this video), there is currently no official support or documentation for it.
• The necessity to compile from source (Rust + CUDA kernel) — Don’t get me wrong, I appreciate Rust, but not all DS teams are familiar with it, which can make it challenging to incorporate custom changes into the library.
• Incomplete documentation: All the information is available in the project’s README. Although it covers the basics, I faced situations where I had to search for additional details in issues or source code (especially challenging for me when dealing with the Rust language).
I believe this is one of the leading contenders in the race. The library is well-written, and I faced minimal challenges during model deployment. If you desire native integration with HuggingFace, this is definitely worth considering. Note that the project team recently changed the license.
You can find TGI Development Roadmap here.
3. CTranslate2

CTranslate2 is a C++ and Python library for efficient inference with Transformer models.
Usage
First, convert the models:
pip install -qqq transformers ctranslate2
# The model should be first converted into the CTranslate2 model format:
ct2-transformers-converter --model huggyllama/llama-13b --output_dir llama-13b-ct2 --force
Make queries:
import ctranslate2
import transformers
generator = ctranslate2.Generator("llama-13b-ct2", device="cuda", compute_type="float16")
tokenizer = transformers.AutoTokenizer.from_pretrained("huggyllama/llama-13b")
prompt = "Funniest joke ever:"
tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(prompt))
results = generator.generate_batch(
[tokens],
sampling_topk=1,
max_length=200,
)
tokens = results[0].sequences_ids[0]
output = tokenizer.decode(tokens)
print(output)
Killer features
• Fast and efficient execution on CPU and GPU — Thanks to a built-in range of optimizations: layer fusion, padding removal, batch reordering, in-place operations, caching mechanism, etc. inference LLMs are faster and require less memory.
• Dynamic memory usage — The memory usage changes dynamically depending on the request size while still meeting performance requirements thanks to caching allocators on both CPU and GPU.
• Multiple CPU architectures support — The project supports x86–64 and AArch64/ARM64 processors and integrates multiple backends that are optimized for these platforms: Intel MKL, oneDNN, OpenBLAS, Ruy, and Apple Accelerate.
Advantages
• Parallel and asynchronous execution — Multiple batches can be processed in parallel and asynchronously using multiple GPUs or CPU cores.
• Prompt caching — The model is run once on a static prompt and the model state is cached and reused for future calls with the same static prompt.
• Lightweight on disk — Quantization can make the models 4 times smaller on disk with minimal accuracy loss.
Limitations
• No built-in REST server — Although you can still run a REST server, I missed having a ready-made service with logging and monitoring capabilities.
• Lack of support for adapters (LoRA, QLoRA, etc.).
I find the library intriguing. The developers are actively working on it, evident from the releases and commit on GitHub, and they also share informative blog posts about its application. The library’s numerous optimizations are impressive, and its primary highlight is the ability to perform LLM inference on the CPU.
4. DeepSpeed-MII

MII makes low-latency and high-throughput inference possible, powered by DeepSpeed.
Usage
Run web server:
# DON'T INSTALL USING pip install deepspeed-mii
# git clone https://github.com/microsoft/DeepSpeed-MII.git
# git reset --hard 60a85dc3da5bac3bcefa8824175f8646a0f12203
# cd DeepSpeed-MII && pip install .
# pip3 install -U deepspeed
# ... and make sure that you have same CUDA versions:
# python -c "import torch;print(torch.version.cuda)" == nvcc --version
import mii
mii_configs = {
"dtype": "fp16",
'max_tokens': 200,
'tensor_parallel': 1,
"enable_load_balancing": False
}
mii.deploy(task="text-generation",
model="huggyllama/llama-13b",
deployment_name="llama_13b_deployment",
mii_config=mii_configs)
Make queries:
import mii
generator = mii.mii_query_handle("llama_13b_deployment")
result = generator.query(
{"query": ["Funniest joke ever:"]},
do_sample=True,
max_new_tokens=200
)
print(result)
Killer features
• Load balancing over multiple replicas — A highly useful tool for handling a high volume of users. The load balancer efficiently distributes incoming requests among various replicas, resulting in improved application response times.
• Non-persistent Deployment — An approach where updates are not permanently applied to the target environment. It is a valuable choise in scenarios where resource efficiency, security, consistency, and ease of management are essential. It enables a more controlled and standardized environment while reducing operational overhead.
Advantages
• Different model repositories — Available through multiple open-sourced model repositories such as Hugging Face, FairSeq, EluetherAI, etc.
• Quantifying Latency and Cost Reduction — MII can significantly reduce the inference cost of very expensive language models.
• Native and Azure integration — The MII framework, developed by Microsoft, offers excellent integration with their Cloud system.
Limitations
• Lack of official releases — It took me several hours to find the right commit with a functional application. Some parts of the documentation are outdated and no longer relevant.
• A limited number of models — No support for Falcon, LLaMA 2, and other language models. There are only a limited number of models you can run.
• Lack of support for adapters (LoRA, QLoRA, etc.)
The project is based on the reliable DeepSpeed library, which has earned its reputation in the community. If you seek stability and a tried-and-tested solution, MII would be an excellent option. Based on my experiments, the library exhibits the best speed for handling a single prompt. Nonetheless, I advise testing the framework on your specific tasks before implementing it into your system.
5. OpenLLM

An open platform for operating large language models (LLMs) in production.
Usage
Run web server:
pip install openllm scipy
openllm start llama --model-id huggyllama/llama-13b \
--max-new-tokens 200 \
--temperature 0.95 \
--api-workers 1 \
--workers-per-resource 1
Make queries:
import openllm
client = openllm.client.HTTPClient('http://localhost:3000')
print(client.query("Funniest joke ever:"))
Killer features
• Adapters support — Connect multiple adapters to only one deployed LLM. Just imagine, you can use just one model for several specialized tasks.
• Runtime Implementations — Use different implementations: Pytorch (pt), Tensorflow (tf) or Flax (flax).
• HuggingFace Agents — Link different models on HuggingFace and manage them with LLM and natural language.
Advantages
• Good community support — The library is constantly developing and adding new functionality.
• Integrating a new model — The developers offer a guide on how to add your own model.
• Quantisation — OpenLLM supports quantisation with bitsandbytes and GPTQ.
• LangChain integration — You can interact with remote OpenLLM Server using LangChian.
Limitations
• Lack of batching support — It’s highly likely that for a significant stream of messages, this could become a bottleneck in your application’s performance.
• Lack of built-in distributed inference — If you want to run large models across multiple GPU devices you need to additionally install OpenLLM’s serving component Yatai.
This is a good framework with a wide range of features. It enables you to create a flexible application with minimal expenses. While some aspects might not be fully covered in the documentation, you will likely discover pleasant surprises in its additional capabilities as you delve into this library.
6. Ray Serve

Ray Serve is a scalable model-serving library for building online inference APIs. Serve is framework-agnostic, so you can use a single toolkit to serve everything from deep learning models.
Usage
Run web server:
# pip install ray[serve] accelerate>=0.16.0 transformers>=4.26.0 torch starlette pandas
# ray_serve.py
import pandas as pd
import ray
from ray import serve
from starlette.requests import Request
@serve.deployment(ray_actor_options={"num_gpus": 1})
class PredictDeployment:
def __init__(self, model_id: str):
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
self.model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
)
self.tokenizer = AutoTokenizer.from_pretrained(model_id)
def generate(self, text: str) -> pd.DataFrame:
input_ids = self.tokenizer(text, return_tensors="pt").input_ids.to(
self.model.device
)
gen_tokens = self.model.generate(
input_ids,
temperature=0.9,
max_length=200,
)
return pd.DataFrame(
self.tokenizer.batch_decode(gen_tokens), columns=["responses"]
)
async def __call__(self, http_request: Request) -> str:
json_request: str = await http_request.json()
return self.generate(prompt["text"])
deployment = PredictDeployment.bind(model_id="huggyllama/llama-13b")
# then run from CLI command:
# serve run ray_serve:deployment
Make queries:
import requests
sample_input = {"text": "Funniest joke ever:"}
output = requests.post("http://localhost:8000/", json=[sample_input]).json()
print(output)
Killer features
• Monitoring dashboard and Prometheus metrics — You can use the Ray dashboard to get a high-level overview of your Ray cluster and Ray Serve application’s states.
• Autoscale across multiple replicas — Ray adjusts to traffic spikes by observing queue sizes and making scaling decisions to add or remove replicas.
• Dynamic Request Batching — It is necessary when your model is expensive to use and you want to maximize the utilization of hardware.
Advantages
• Extensive documentation — I appreciate that the developers have dedicated time to this aspect and approached documentation creation diligently. You can find numerous examples for almost every use case, which is very helpful.
• Production-ready — In my opinion, this is the most mature framework among all presented in this list.
• Native LangChain integration — You can interact with remote Ray Server using LangChian.
Limitations
• Lack of built-in model optimization — Ray Serve is not focused on LLM, it is a broader framework for deploying any ML models. You will have to do the optimization by yourself.
• High entry barrier — The library is sometimes overloaded with additional functionality, which raises the entry threshold, making it challenging for newcomers to navigate and understand.
If you need the most production-ready solution that is not just about deep learning, Ray Serve is a great option. It is best suited for the enterprise, where availability, scalability, and observability are important. Moreover, you can use its vast ecosystem for data processing, training, fine-tuning, and serving. And finally, it is used by companies from OpenAI to Shopify and Instacart.
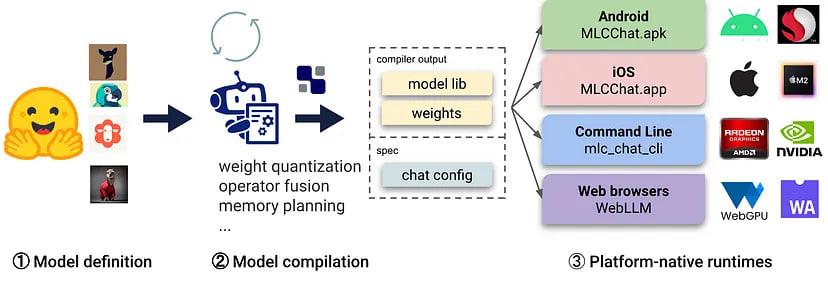
7. MLC LLM

Machine Learning Compilation for LLM (MLC LLM) is a universal deployment solution that enables LLMs to run efficiently on consumer devices, leveraging native hardware acceleration.
Usage
Run web server:
# 1. Make sure that you have python >= 3.9
# 2. You have to run it using conda:
conda create -n mlc-chat-venv -c mlc-ai -c conda-forge mlc-chat-nightly
conda activate mlc-chat-venv
# 3. Then install package:
pip install --pre --force-reinstall mlc-ai-nightly-cu118 \
mlc-chat-nightly-cu118 \
-f https://mlc.ai/wheels
# 4. Download the model weights from HuggingFace and binary libraries:
git lfs install && mkdir -p dist/prebuilt && \
git clone https://github.com/mlc-ai/binary-mlc-llm-libs.git dist/prebuilt/lib && \
cd dist/prebuilt && \
git clone https://huggingface.co/huggyllama/llama-13b dist/ && \
cd ../..
# 5. Run server:
python -m mlc_chat.rest --device-name cuda --artifact-path dist
Make queries:
import requests
payload = {
"model": "lama-30b",
"messages": [{"role": "user", "content": "Funniest joke ever:"}],
"stream": False
}
r = requests.post("http://127.0.0.1:8000/v1/chat/completions", json=payload)
print(r.json()['choices'][0]['message']['content'])
Killer features
• Platform-native runtimes — Deploying on the native environment of user devices, which may not have Python or other necessary dependencies readily available. App developers only need to familiarize themselves with the platform-naive runtimes to integrate MLC-compiled LLMs into their projects.
• Memory optimization — you can compile, compress, and optimize models using different techniques, allowing you to deploy them on different devices.
Advantages
• All settings in JSON config — allow you to define the runtime configuration for each compiled model in a single configuration file.
• Pre-built Apps — you can compile your model for different platforms: C++ for the command line, JavaScript for the web, Swift for iOS, and Java/Kotlin for Android.
Limitations
• Limited functionality of using LLM models: no support for adapters, can’t change precision, no token streaming, etc. The library is mainly focused on compiling models for different devices.
• Support only grouping quantization — although this method has shown good results, other approaches for quantization (bitsandbytes and GPTQ) are more popular in the community. Quite possibly they will be better developed by the community.
• Complicated installation — It took me several hours to install the library correctly. Most likely, it is not suitable for beginner developers.
If you need to deploy an application on an iOS or Android device, this library is exactly what you need. It will allow you to quickly and natively compile and deploy the model to devices. However, if you need a highly loaded server, I would not recommend choosing this framework.
Takeaways
Selecting a clear favorite was challenging for me. Each library has its unique advantages and drawbacks. LLMs are still in the early stages of development, so there is no single standard to follow yet. I encourage you to use my article as a foundational starting point in choosing the most suitable tool for your requirements.
I did not touch upon the topic of model inference costs, as they vary significantly based on your GPU vendor and model usage. However, some helpful cost-cutting resources can be found in the bonus section below.
Bonus section
During my experiments, I used some services and libraries that could be useful for you as well:
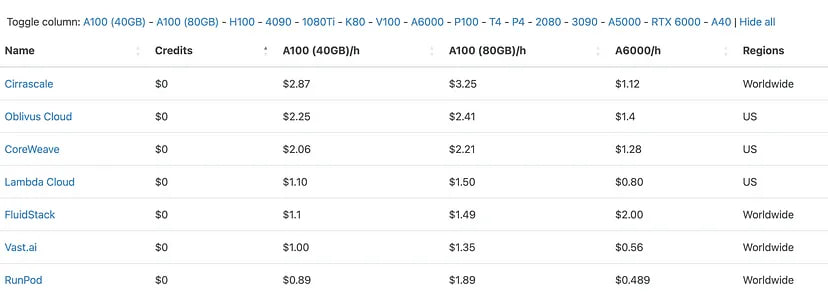
• Cloud GPU Comparison: Here, you can find the best prices from different providers for servers with GPUs.
• dstack: Allows you to configure the necessary environment for LLM inference and launch it with a single command. For me, this helped reduce expenses on idle GPU servers. Here’s just an example of how quickly you can deploy LLaMA:
type: task
env:
- MODEL=huggyllama/llama-13b
# (Optional) Specify your Hugging Face token
- HUGGING_FACE_HUB_TOKEN=
ports:
- 8000
commands:
- conda install cuda # Required since vLLM will rebuild the CUDA kernel
- pip install vllm
- python -m vllm.entrypoints.openai.api_server --model $MODEL --port 8000
And then all you have to do is just run the command:
dstack run . -f vllm/serve.dstack.yml